

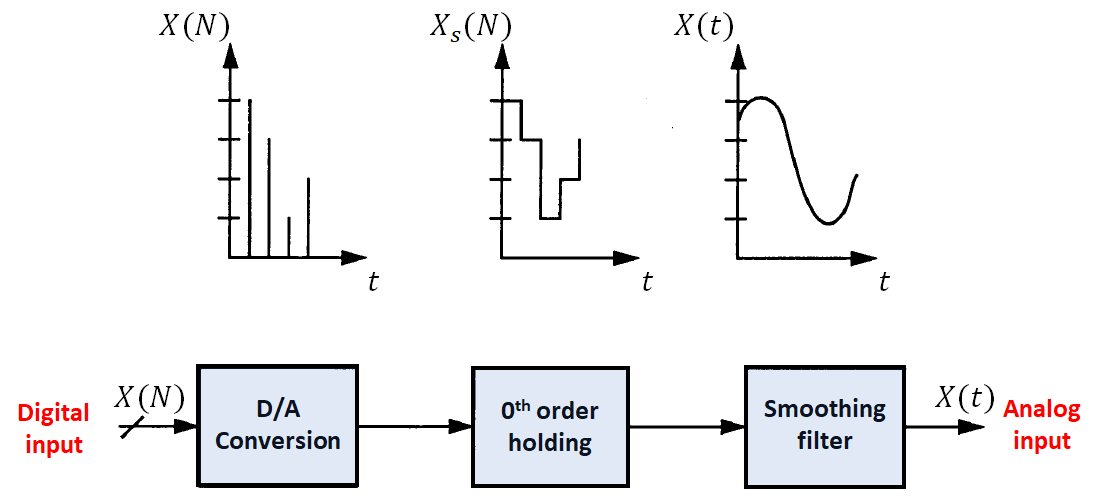
Basic Terms
Audio File
| Terms | Details |
|---|---|
| Bitrate | The bitrate of an audio file is the number of bits of audio data stored per second, which can be variable or constant based on the encoding. Learn more |
| Lossy | Lossy codecs aim to make file sizes small, even if it means compromising in quality. Quality of the sound varies wildly between formats and bitrates, with higher bitrates sounding better. Beyond the transparency threshold, everything will sound the same. Learn more |
| Lossless | Lossless, also known as lossless compression, which is compression that preserves all data from the source file. Lossless compression is completely indistinguishable from the source file. Learn more |
| Spectrogram | A measure of frequency density over time. A spectrogram can be viewed as a graph, with frequency density represented by color. The spectrogram can be used to scrutinize the quality of an encoding. Learn more |
Release
| Terms | Details |
|---|---|
| Single | A music release containing 1 or 2 songs. |
| Maxi Single | Another term for EP, mostly used in Europe. |
| EP | Extended Play, a release usually containing 4 to 6 tracks. |
| LP | Long Play, a full album release usually containing 10 to 12 tracks. |
| Album | An album is a collection of songs, either by a singular artist, vocalist, producer, or label. Sometimes, albums can even be compilations of multiple unrelated parties. |
| Compilation | An album compiling tracks from different recordings of one or multiple artists. |
| Label | A company that publishes, distributes and promotes the music of their affiliated artists. The three biggest are Sony, Universal & Warner. |
Hardware
| Terms | Details |
|---|---|
| IEM | Short for “In Ear Monitor”. These are much like earbuds, however, they have nozzles and tips attached to the end where audio comes out. This makes it such that the “monitor”, or speaker, goes “in ear”. Earbuds, alternatively, will rest on the ear canal without actually going in. The benefit of an IEM is that it creates a seal within your ear, which can allow for the bass response to be maintained much easier. Learn more |
| DAC | Short for “Digital-to-Analog Converter”. In terms of music, the DAC is the part of the chain that converts source files into analog signals that a headphone, speaker, or IEM can play back. Learn more |
| Amp | Short for “Amplifier”. In terms of music, the amp takes the converted signal from a DAC, or other analog source, and increases that signal's amplitude. This process is what makes audio louder. Any time you interact with a knob or volume rocker in order to make music louder or quieter, odds are you're interfacing with an amplifier. Learn more |
| Speaker | Speakers shoot sound out towards the user. They consist of a subwoofer, woofer and tweeter. The subwoofer is usually disconnected from the woofer and tweeter pairing. Learn more |
Tools
| Terms | Details |
|---|---|
| DAW | Digital Audio Workstation (DAW) is software used for recording, editing, mixing, and producing audio files. DAWs offer a comprehensive environment for creating music, podcasts, sound design, and other audio projects, combining tools for sequencing, synthesis, and audio processing. Users can manipulate audio tracks, apply effects, and integrate virtual instruments all within a single platform. Examples of popular DAWs include FL Studio, Ableton Live, Cubase, Pro Tools, Reaper, and Logic Pro. Each DAW offers unique features and workflows, catering to different styles of music production and audio engineering needs. |
| Voice synthesizer | Voice synthesizers (e.g., Vocaloid, Synthesizer V, UTAU) work by taking user input in the form of musical notes and lyrics, then processing this input to generate a synthesized singing voice. They're created using voice banks, which consist of recordings of real people's voices. Each voice bank is typically designed for a specific language and while it is possible to create songs in other languages using them, it requires more fine-tuning to achieve good results. |
Audio file
Audio Signal
| Type | Description |
|---|---|
| Physical | Physical audio signals are produced by vibrating resonant objects. These vibrations travel through a medium (solid, liquid, or air) and form continuous wave functions. |
| Analog | An analog audio signal is a continuous wave function, characterized by a constantly changing voltage. Microphones or other receivers convert physical audio signals into analog signals. This continuous nature means the signal contains an infinite number of data points, making direct digital processing impractical. |
| Digital | A digital audio signal is also a wave function. It is discrete, meaning that there are only two logical states of potential. These waves can be interpreted as logical 1s and 0s, allowing for complex logical operations. |
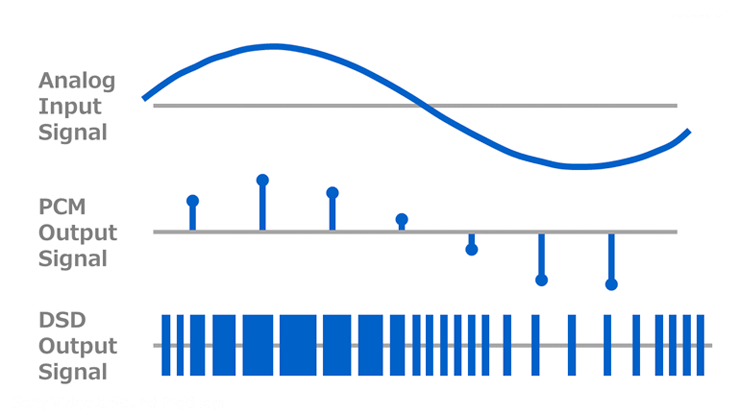
Pulse Code Modulation (PCM)
Pulse Code Modulation (PCM)
PCM (Pulse Code Modulation) is the most widely used audio encoding method. It involves sampling the audio signal at regular intervals and quantizing the amplitude of each sample into a discrete value. Music is generally recorded in a PCM format. Here are a few related terms for PCM:
- Sample Rate: The number of samples taken per second from the analog audio signal.
- Bit Depth: The number of levels used during quantization. These levels define the number of amplitudes available to the encoder. Higher levels mean a wider range of amplitudes per sample.
- Channel: The number of individual audio signals in the recording (e.g., mono, stereo).
Direct Stream Digital (DSD)
Direct Stream Digital (DSD)
Direct Stream Digital (DSD), a product developed by Sony & Philips, is known for its high-resolution audio quality. However, DSD files are relatively rare due to their low popularity. Several factors contribute to this, including their huge file size, the difficulty in mastering and editing during production, and the greater efficiency of PCM files in various aspects.
DSD is an audio encoding method that uses 1-bit delta-sigma modulation. It samples the audio signal at a very high sample rate, representing changes in signal density rather than amplitude levels, and has only 1 bit of amplitude. The most popular DSD standard is .dsf, but there are other standards as well.
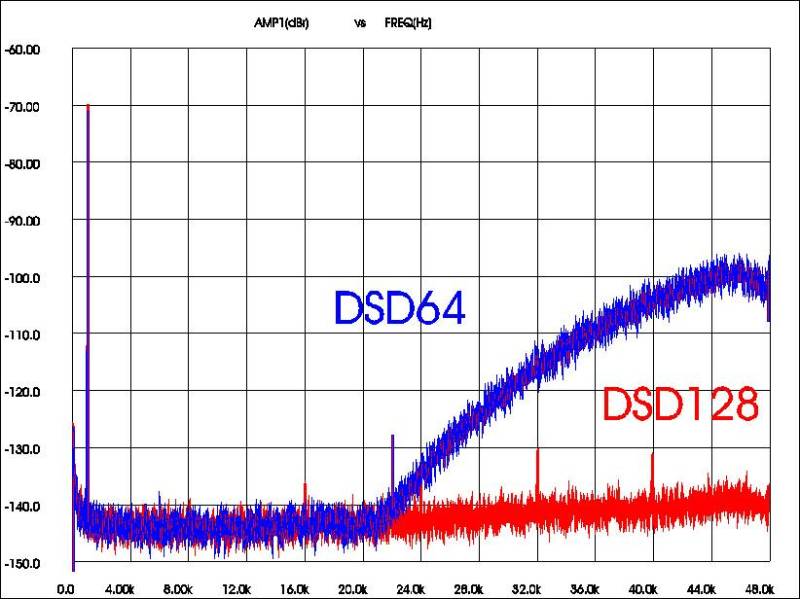
DSD files can be classified based on their sampling rate:
| DSD Type | Sampling Rate | Relation to CD Audio (44.1kHz) |
|---|---|---|
| DSD64 | 2.8224 MHz | 64 times |
| DSD128 | 5.6448 MHz | 128 times |
| DSD256 | 11.2896 MHz | 256 times |
| DSD512 | 22.5792 MHz | 512 times |
| DSD1024 | 45.1584 MHz | 1024 times |
DSD’s high sampling rate allows for a wide dynamic range, even with a 1-bit depth. Factors like noise shaping and dithering also contribute to the audio quality. Noise shaping moves noise to the ultrasonic range. For example, DSD64 files start to see noise increase past 20kHz, requiring the DAC to filter it out. Higher DSD rates experience less noise rise, pushing it further into the ultrasonic range and making noise shaping more linear, which eases the DAC's job.
Analog to Digital
Analog signals are signals with an alternating current. The “analog” part refers to how the signal usually correlates to some sort of physical property. For example, a signal generated by a power generator would be analogous to the speed at which the rotation of the generator occurs. In terms of audio, the signal will correlate to the oscillation of the driver used to reproduce the sound. In other words, how the sound would vibrate through the air.
In order to process the analogous signals digitally, we need to perform a process called discretization. This allows for analog signals to be represented in either their amplitude or time domains for digital analysis.
- Discretization of time -> Sampling
- Discretization of amplitude -> Quantization
Sampling
Sampling is the process of taking a signal and splitting it based on an algorithm. Sampling can be done in the frequency, amplitude, or time domains. Each process involves processing the data differently, but allows for accurate reproduction of an analog signal in the digital realm.
When referring to audio signals, sampling is the process of splitting signals by time (Hz). This allows for every single frequency in the audible spectrum to accurately be recorded. Learn more about this in sample rate .
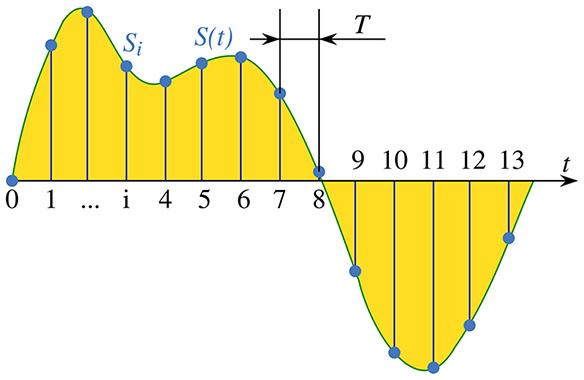
Sample Rate
The amount of samples taken from the analog audio signal per cycle is known as the sample rate. As it's a per-second measurement, the unit is Hz (Hertz). Hertz are a measurement of frequency, or how many periods of a wave exist per second.
A higher sample rate means more data points are taken per second. This doesn't necessarily result in a higher quality signal. A higher sample rate allows for the sampling of larger frequencies, but for the human audible spectrum, there are no advantages.
For listeners, 44.1kHz is sufficient to represent all humanly audible frequencies. 44.1kHz is the standard sampling rate for CDs, and 48kHz is the standard for DVDs and streaming services (originally brought forth to aid in timing with TV broadcasts). There is no functional difference between the two, beyond resampling issues that may arise between the mediums.
Higher sampling rates are often desirable by producers as it allows them to modify the audio more flexibly without adding additional noise. It's not really relevant for playback.
Dithering
Dithering
Dithering is a process used when converting from different bit widths. Converting raw audio data to a different bit width will induce quantization errors during the conversion process. These are errors caused by averaging amplitudes. A dither signal can be applied to the audio before conversion, which is effectively noise. While noise may seem undesirable, it actually improves the quantization and significantly reduces the errors during the conversion. The noise is not perceivable to humans, and does not effect the quality of a mix whatsoever.
Nyquist–Shannon Sampling Theorem
Nyquist–Shannon Sampling Theorem
Nyquist Sampling Theorem dictates how sampling should be done in order to avoid aliasing. The primary technique is to utilize a sample rate that is twice that of the desired maximum frequency. To ensure that the entire spectrum is being sampled, a very small margin should be added to the sample frequency. For example, while the human hearing spectrum is said to cap out at 20kHz, the desired sampling frequency was chosen to be 20.05kHz. A small margin such as this aids in ensuring the desired frequencies are captured during sampling. The sample rate for audio was thus twice that value, or 44.1kHz.
Another condition is bandlimiting. During the conversion of signals, high frequency distortion is added to the result. A band-pass filter helps to isolate the target frequencies from this distortion. Aliasing occurs if this distortion is not filtered. The folded wave interferes with the main wave and creates a new, unwanted sound wave.
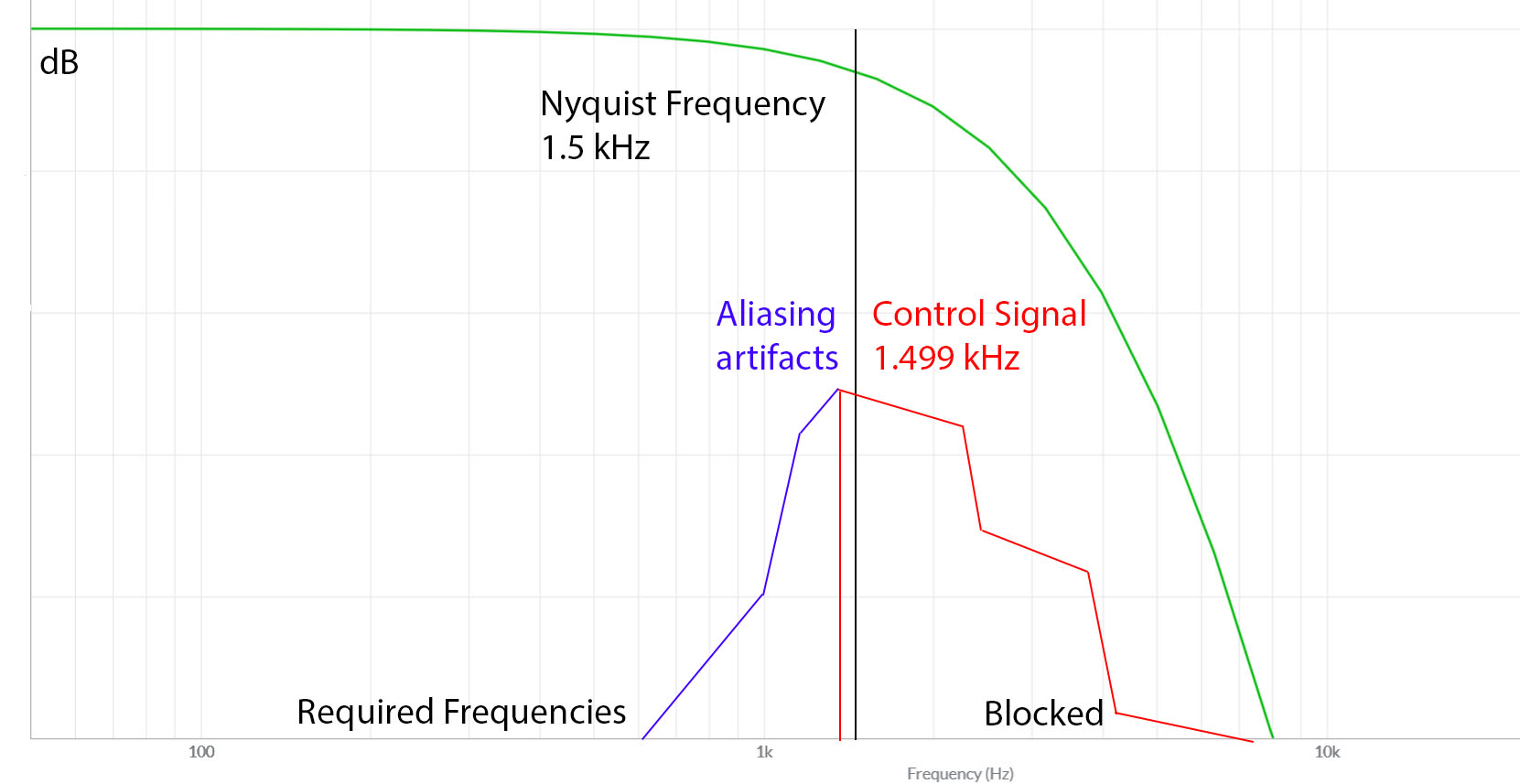
To remove aliasing, a low pass filter (aka anti-aliasing filter) is added into both the ADC and DAC. Software will additionally include filters to remove aliasing in digitally generated audio signals. It's not practically possible to remove higher frequencies at the desired Nyquist frequency, so a buffer space is kept between the desired frequency and the Nyquist frequency. The buffer space depends on hardware capability.
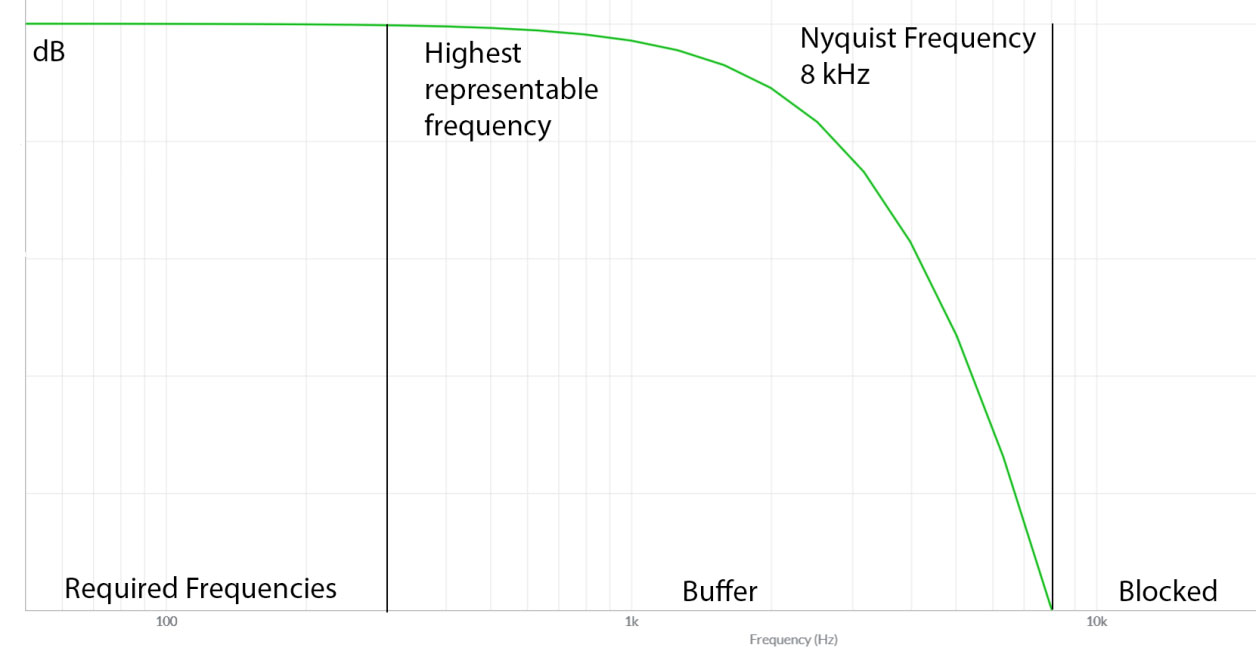
Learn more about the Nyquist sampling theorem .
Bit Depth
Bit depth indicates how many levels are used during quantization. Bit depth, also known as the number of levels, is defined by a power of 2levels of bit depth.
- 8bit -> 256 levels
- 16bit -> 65,536 levels
- 24bit -> 16,777,216 levels
The increase in levels is exponential. The higher the level number, the closer the amplitude matching between analog and digital signals and the lower the amplitude of the resulting quantization noise.
Increasing the bit depth blindly is counter-intuitive. For example, increasing the bit depth from 16 to 24 bits produces a barely perceivable enhancement. The file size, however, becomes much larger with the increase in depth.
Dynamic Range
Dynamic Range
The dynamic range is the distance between the loudest and quietest sounds within a mix. The range can be calculated using this formula,
Signal-to-Quantization-Noise Ratio = 20log(2bit depth)dB + 1.76dB
This formula provides the following dynamic ranges: (without any dithering applied),
- 8bit -> 49.93dB
- 16bit -> 98.089dB
- 24bit -> 146.25dB
16-bit audio produces a maximum possible undithered dynamic range of ~96 dB, and with noise-shaped dithering applied, the dynamic range can increase upwards of 120dB. A average quiet home room won't have a significantly lower noise floor than 30 - 40dB. The minimum threshold at which a listener should experience a noise floor louder than that of ambient noise is well beyond the point where one would cause damage to their hearing. Bit depths greater than 16 are far more relevant for audio processing, rather than playback.
24-bit audio possesses a dynamic range exceeding the human hearing capabilities. With the increase in file size, it may be hard to justify the storage of these higher bit width files.
Bit rate
Bit rate is the amount of data streamed per second. For an audio file, there are three types:
| Bit Rate Types | Description |
|---|---|
| Constant (CBR) | The bit rate remains constant throughout the entire file (including bits storing silence). Since the bit rate is constant, the file size is more predictable. |
| Variable (VBR) | VBR adjusts the bit rate based on content complexity, which can lead to a more efficient use of bits, as well as smaller file sizes when compared to CBR encoding. |
| Average (ABR) | ABR is a middle ground between CBR and VBR. The bitrate is allowed to fluctuate, so long as an average value is maintained. This is considered an inferior standard when compared to the other two. |
Codec
A codec is a standard used to encode and decode a data stream. Using codecs, data is stored in a container. Codecs are one of the most important factors in determining audio quality. There are several codecs used in the audio medium.
| Type | Codec |
|---|---|
| Uncompressed Lossless | WAV, AIFF |
| Compressed Lossless | FLAC, ALAC, APE, WavPack |
| Compressed Lossy | MP3, Vorbis, Opus, AAC |
Uncompressed Lossless
Uncompressed lossless codecs are pretty old. They use CBR/Constant Bitrate encoding. CBR encoding ensures no data is lost, but the resulting file size is very large. WAVs consist of only a header, metadata, and raw quantization metrics. Devices can easily perceive this sort of encoding, leading to its relevance even today. As such, it's still widely used in music studios. As a consumer, they remain a bloated and unwanted format.
Spectrogram
Spectrograms a.k.a spectral analysis are a reliable method to identify audio quality. Spectrograms plot the frequency spectrum across the time domain. Perceived loudness of these frequencies are represented by the color of the wave. The colors can then be decoded into a decibel rating from the legend on the right. This type of graph is useful in determining the sort of compression applied to an audio file. The depth at which these frequencies extend into the higher ranges indicate the type of compression utilized. Here, Spek has been used to analyze. The following are a couple of examples of different levels of quality:
FLAC 24/48
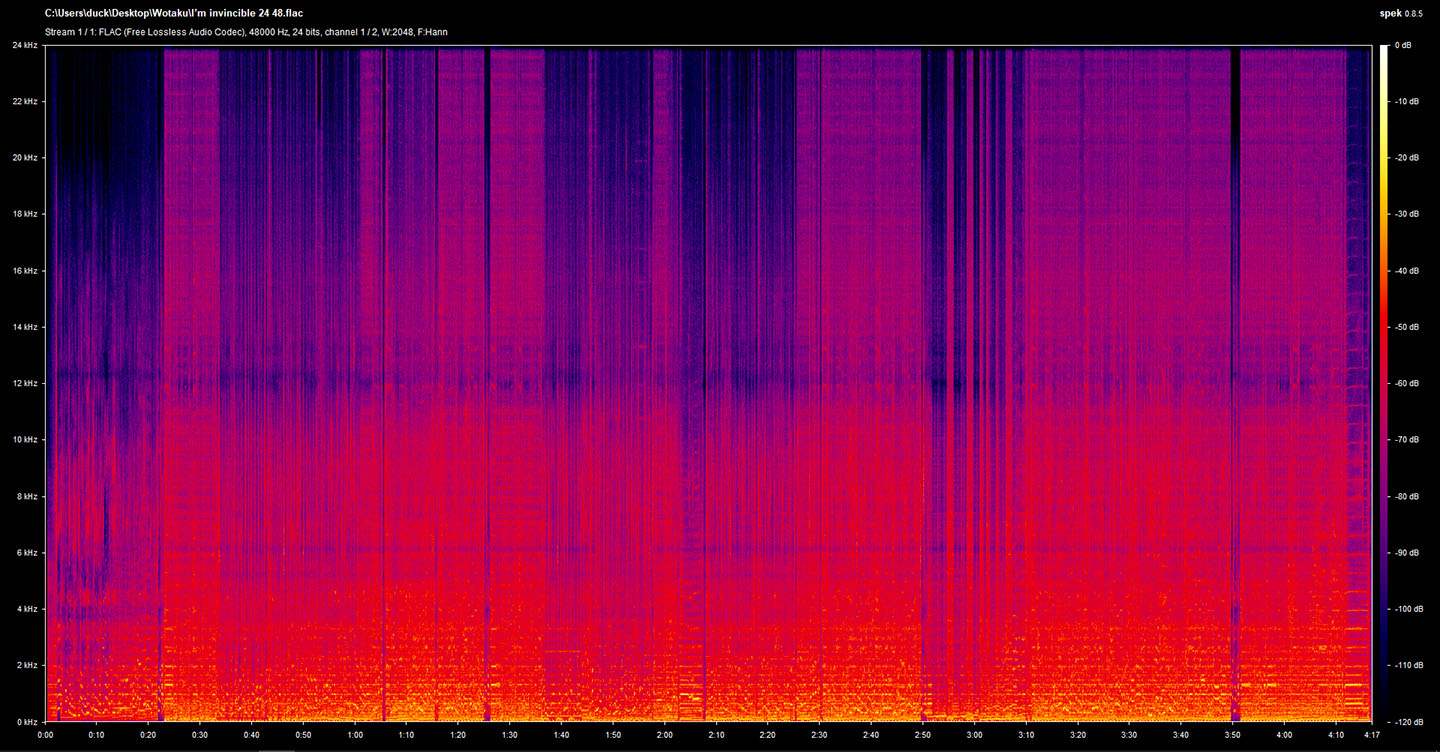
The above figure is a spectrogram of a 24 bit, 48kHz FLAC. A 48kHz FLAC can support frequencies up to 24kHz. This value comes from halving 48kHz (following Nyquist–Shannon Sampling Theorem).
Spectrogram
In short, analyzing a file can help determine the authenticity of the quality. A FLAC file cant always be taken at face value. If it sounds low quality, it could potentially be the result of a bad transcode. Software such as spek allows the user to analyze music and prevent the sharing of low quality, unwanted encodes.
Click here for higher res specs.
Container
Container is the extension name we see at the end of the file. This can be same as codec (e.g., FLAC & .FLAC) or different (e.g. ALAC & .m4a). Containers store all the data. The data is (typically) stored in different parts. These structures can change based on the container. This can be oversimplified like this:
- Header: This section contains info about file format, size and signature.
- Audio data: This section is the main part. It contains the encoded audio file.
- Metadata: Metadata can contain info about title, artist, album, genre etc. (e.g., ID3, Vorbis comment)
- Others: There can be other parts too containing e.g. cue files.
Example: Ogg Container Structure
Example: Ogg Container Structure
.ogg is one of the most widely used audio containers. It's very flexible. .ogg is structured as a series of pages which makes it easier to stream. Each page contains segments of audio data stream (or the other types of stored encoded media). Here we will describe a watered down version of .ogg container structure. You can read the full specification here
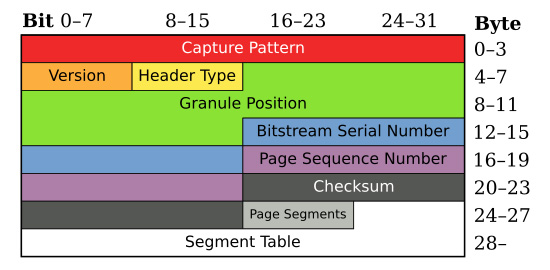
As mentioned before data in .ogg container are divided in multiple pages. These pages have identical structure and connect together to give a gapless data stream. The parts in a single page are:
Capture pattern / Sync code: This number used to ensure sync when parsing
.oggfile. Also assists in resyncing a parser in cases where data has been lost or is corrupted.Version: The version of the Ogg bitstream format.
Header type: It indicates whether the packet is the beginning or ending of the data stream or continuation after the previous packet.
Granule position: It is the time marker by the codec which shows the number of samples and/or other data.
Bitstream serial number: This is a unique number that identifies a page as belonging to a particular bitstream.
Page sequence number: This gives every page a chronological number which starts from 0.
Checksum: A CRC32 checksum of the data in the entire page to check whether or not the page is altered or not.
Page segments: It indicates the number of segments that exist in this page as well as how many bytes are in the segment table that follows this field. One single page can have max 255 segments.
Segment table: To understand this, we need to define three key terms: segment, packet, and segment table.
- Segment: A segment is a small piece of data, up to 255 bytes in size, like a tiny chunk of information.
- Packet: A packet is the meaningful unit of data that the decoder processes. A packet can consist of one or more segments. If a packet's data is too large to fit into a single segment, it is spread across multiple segments.
- Segment table: The segment table is a list that specifies the sizes of the segments on a page. Each entry in this table is an 8-bit (1 byte) value that indicates the length of a segment.
Within the segment table:
- If a segment's length is 255, the next segment is combined with it as part of the same packet.
- If a segment's length is between 0 and 254, this indicates the end of the packet.
- If a packet's total length is a multiple of 255, the final segment will have a length of 0.
- If the last packet continues onto the next page, the final segment’s length is 255, and a continuation flag on the next page signals that the packet continues from the previous page.
Metadata: In
.ogg, VorbisComment is the most common metadata container.
Most container formats support multiple codecs, for example .m4a (audio-only MP4 files) may contain AAC-encoded audio or ALAC-encoded audio (FLAC and Opus are also supported codecs as of newer revisions of the standard). Some codecs, like MP3, do not have/use codified container formats, and therefore the file format doesn't support other codecs.
Containers by themselves do not dictate whether the contained audio is lossy or not. That depends on the codec, for example the .ogg container format typically contains any of these codecs:
- OggPCM (uncompressed lossless)
- FLAC (compressed lossless)
- Vorbis (lossy)
- Opus (lossy)
.ogg can contain other types of media too. Such as: picture, video and text files.
Some containers are renamed versions of other containers. For example, .opus and .oga are audio-only versions of .ogg, just as .m4a and .m4b are audio-only versions of .mp4.
Audio files can also be embedded in non-audio specific containers, such as .mkv and .mp4, which include audio alongside video bitstreams.
Audio Source
| Type | Source |
|---|---|
| Analog | Vinyl, tape |
| Digital | CD, DVD, Digital Store, Streaming |
- For analog sources, you have to use an analog-to-digital converter to get the digital file from the physical medium.
- For digital sources, audio files are already present in digital format. You have to use ripping software to rip from these.
- Among streaming services:
- Lossless: Qobuz, Apple Music, Tidal, Amazon Music, Deezer
- Lossy: Spotify, YouTube Music, SoundCloud
More about analog sources
More about analog sources
Two common analog sources are the vinyl and the cassette.
- Vinyls are large discs that contain grooves in a spiral fashion. These grooves are proportional to that of the sin wave embedded into them. A needle can travel along these grooves in order to reproduce the signal as an alternating current. To achieve this, the vinyl is placed onto a device called a turntable, which spins the disc at a specific speed in order to accurately reproduce the sound. Due to the nature of the needle moving along the grooves, many claim that vinyls will lose sound quality over time. While this is very true, most people buying vinyls today will not listen to them often, so their lifespan can actually be quite long.
- Cassettes, also referred to as tapes, contain magnetic strips with sound information superimposed into them. This works by exposing the magnetic tape to an induced magnetic field. The field strength is proportional to the frequencies of the audio data being imposed. The magnetized particles then align in certain patterns within the tape, encoding the audio. Cassettes can be recorded and played back in a device known as a tape deck. Recording can be achieved on most tape decks, allowing the user to make tape recordings of whatever they like.
Transcoding
Transcoding is the process of converting audio files from one codec (or format) into another. As mentioned before in codec section, there are 3 possible types of audio files:
- Uncompressed Lossless (UL)
- Compressed Lossless (CL)
- Lossy (L)
Transcoding audio to higher bit rate, bit depth or sample rate is a pointless conversion. New data is not created in the process, however, data is reserved for the increased resolution. This process only serves to increase the file size.
Dos
| Input | Output | Description |
|---|---|---|
| UL | CL | Uncompressed lossless (CBR) files are converted into compressed lossless (VBR) files to decrease the file size significantly. |
| CL | CL | This sort of conversion is usually only performed for compatibility reasons. It’s also common to perform a transcode like this if the user wanted to decrease the sample rate/bit depth of a file. Converting from one sample rate/bit depth to another will induce a slight detail loss. For more information on why this happens, see Spectrogram. The section under FLAC 16/44.1 expands on this phenomenon. |
| UL/CL | L | Transcoding from a lossless source to a lossy format is done to save space. To ensure quality, it's best to keep your audio above your transparency threshold or standard bit rates, such as MP3 320, MP3 V0, or Opus 256. |
Transcoding
The process
To learn how to transcode using Foobar2000, read this guide .
Other File types
Hardware

Hardware refers to the devices within the signal chain to reproduce listenable audio. The 3 core devices are the DAC, AMP, and playback device. To briefly explain the signal chain, digital audio needs to be sent to a DAC in order to be converted into a usable analog signal. That analog signal is then amplified to bring it to a listenable volume. Finally, a headphone, IEM, or speaker is plugged into the amplifier to reproduce the sound. This chain holds true for any form of digital media, but analog sources do not require a DAC, as the audio signal is already in the analog form.
DAC
The DAC, or Digital to Analog Converter, takes in digital bitstreams and converts them into analog signals. They come in two distinct form factors: desktop devices or dongles.
- Dongles: A dongle is intended for use with a phone, and generally has an amplifier built in. This makes the dongle a completely standalone device, and you only need to plug it in to make it work. Within this class also exist larger portable DAC/AMPs. These devices have internal batteries, but are otherwise functionaly similar to dongles.
- Desktop DAC: The desktop DAC, alternatively, will rest on a surface. It's much larger and isn't intended to be used portably. It takes in external power from the wall and can offer unbalanced or balanced analog outputs. Desktop DACs are intended to be paired with an external tabletop amplifier. Combination desktop DAC and Amp units exist, although they are less common.
Amp
The amp, or amplifier, takes in analog signals and outputs an amplified version. This process makes the signal louder. An amp can take in a signal from either a DAC, or some other analog source.
There are two types of amplifiers: unbalanced single ended, and balanced.
- Unbalanced amplifiers take in an unbalanced signal, such as one fed from an RCA cable, and outputs an unbalanced signal. An unbalanced signal consists of 3 channels: a left audio channel, a right audio channel, and a ground wire. This type of signal mode is also known as single ended.
- Balanced amplifier takes in a balanced signal, such as one fed from an XLR cable, and outputs a balanced signal. A balanced signal, unlike its unbalanced counterpart, contains 2 copies of the signal. These one of these signals is in opposite phase to the other. These signals are combined back into a singular signal in the device they feed into. Functionally, balanced signals are utilized to decrease the amount of noise a wire picks up as a signal travels along it. Practically, this noise shouldn't exist in shorter unbalanced connections, such as those that would be used on a headphone or speaker. However, balanced signals operate on a higher voltage, which allows your amp to deliver a higher wattage to your load. Depending on the architecture, this may not be true. A higher overall wattage to the load is a good rule of thumb for balanced connections regardless.
The primary difference in amplifiers is how much wattage they can output. Amplifiers come in the form of dongles, desktop sized devices, or large AVRs intended for speakers. Dongles will (generally) output less wattage than desktop sized amplifiers, and desktop sized amplifiers will provide less wattage than an AVR. Dongles can have a DAC embedded within them, making them convenient portable all-in-one solutions. You can tell by the type of connector they use as an input. If the dongle terminates in a connector such as a usb-c, which is a digital input, it’s going to have a DAC.
Playback Device
Playback devices come in many forms, but only the most common will be covered. Specifically the headphone, IEM, and speaker.
Headphone
A headphone is 2 speaker drivers held together by a headband. They can be wired, bluetooth, or wireless with a dongle. To briefly explain the differences:
Wired headphones are passive devices that can be plugged into anything with an audio jack. If it terminates in a 3.5mm or usb-c, then it may be plugged into its respective port. Bluetooth headphones are wireless, although many still offer a cable for an optional passive use.
Audio sent via bluetooth is always compressed with lossy compression, and even with modern bluetooth standards, there is no getting around that. Wireless headphones aren't restricted by the bluetooth encoding standards. The audio may be sent losslessly to the device. The downside is that they typically require a hub or wireless dongle to connect to. This severely limits the amount of devices they could potentially be connected to.
Headphones can have two distinct varieties. Closed back & Open back headphones.
Closed back designs involve a sealed backplate to enclose the driver. This is the most common design, although it presents a larger challenge for acoustically tuning the headphone. When a driver is sealed, the audio that is hitting the backplate must be properly filtered in order to provide a pleasant sound for the listener. This filtering can be achieved with physical design solutions, such as foams, felts, or vents for certain frequencies.
Open back headphones, alternatively, utilize a perforated backplate. This backplate allows sound to be shot outside of the headphone, yielding a less restrictive physical design. There are other benefits, such as open backs generally producing a wider soundstage, which is how far away a sound is perceived from the listener. Open backs are regarded as being easier to tune than closed backs, and some believe the sound of an open back is “more natural.” Even with these benefits, open backs remain a less commonly owned variant. Open back headphones project sound outside of the headphone. Most users seek privacy in the content they listen to, making a closed back a more private and desirable option.
Frequency Response
Summary
The frequency response shows how something sounds across the frequency spectrum, in terms of gain. It can be used to quickly understand how loud the bass, mids, and highs are reproduced.
No one driver will reproduce the entire listenable frequency spectrum, that being 20 Hz to 20kHz, flatly. The loudness of frequencies will always vary throughout the spectrum. The measure of the magnitude of response of the frequency spectrum is known as the frequency response. The frequency response would be the most perceivable difference between playback devices.
The following image is the frequency response of a common headphone, the Sennheiser HD 600:
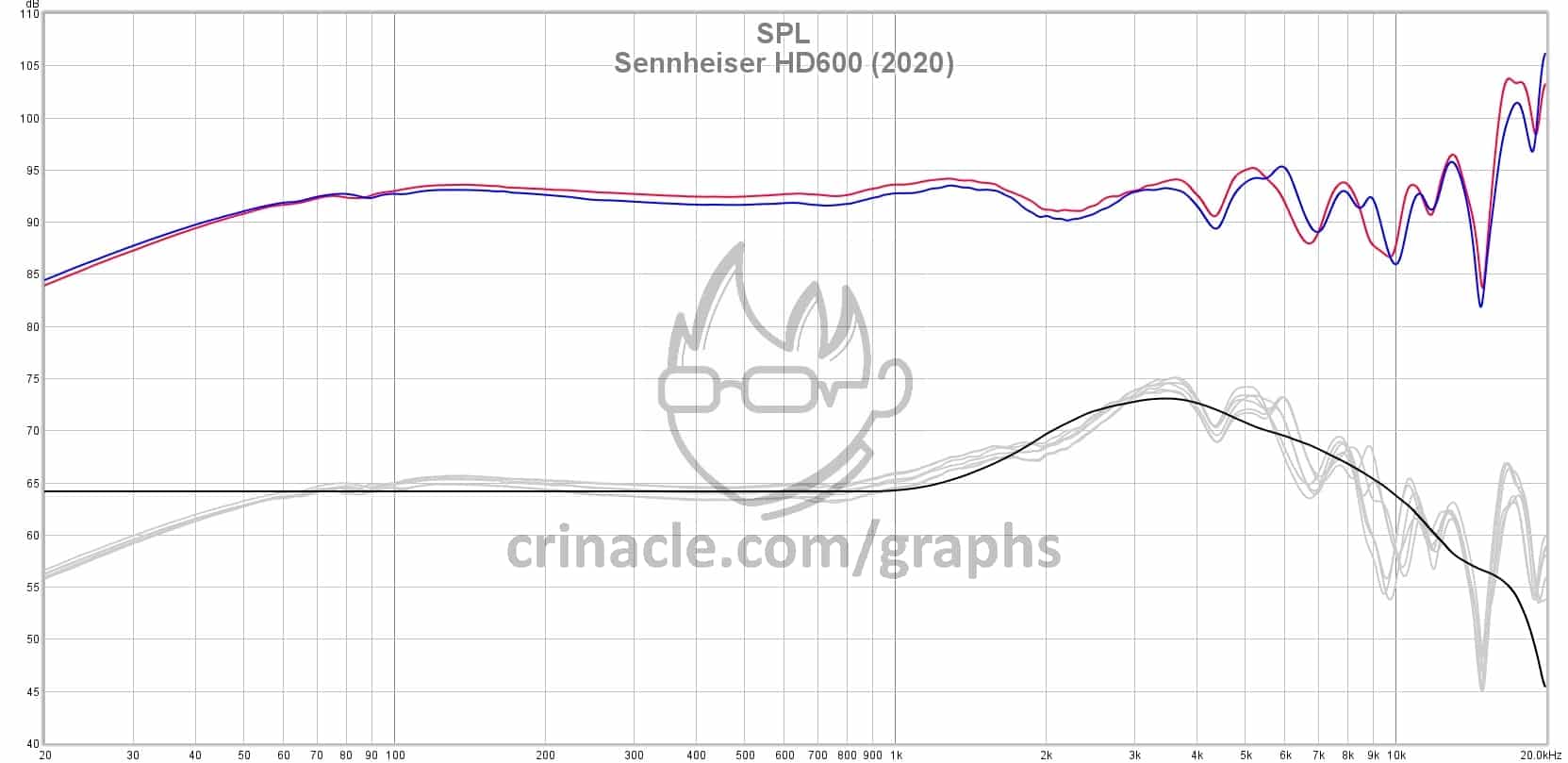
The blue and red lines are the left and right drivers of the headphone. The X axis is the frequency spectrum, increasing from 20Hz to 20kHz, and the Y axis is the perceived loudness. Just for example, at around 30Hz the graph shows a gain of about 60dB. The black line is what the raw measurement was compensated to. That means that the original slope of the blue and red lines were superimposed on the curve depicted by the black line. This is done because the human ear processes frequencies in a strange, non linear manner. The compensation is an attempt to try to more accurately depict how the headphone would sound to the human ear.
The response can be analyzed like so: Crinacle adds the bold lines at 100Hz and 1kHz to separate the bass frequencies from the mid frequencies, and the mid frequencies from the high frequencies. The bass section contains bass tones, such as a kick drum. The mids contain a majority of the sounds in a song, everything from vocals to guitars to synths. The highs mostly consist of a niche subset of instruments, such as cymbals and brass instruments, as well as detail for the lower frequencies. Female vocals may also bleed into this range. The most noticeable portion of a response like this is how the bass is rolled off under about 80Hz, meaning it gradually decreases in gain down to 20Hz. The overall response tries to stay flat, or neutral, but the high frequencies suffer some dips and peaks throughout the spectrum.
Equalization
Summary
Eq allows for altering of playback. Sound can be flavored to a user’s preferences, with no cost to the user.
Equalization, also shortened to eq, allows you to alter the frequency response of a playback device. This can be very useful if a particular section of the frequency response is not so pleasant to listen to, such as it being too loud or too quiet. Equalization can easily be performed on a desktop computer or a mobile phone, although there are also dedicated devices.
While this is a very powerful tool, there are still limitations to equalization. If the users wanted to make certain frequencies louder, it's not as simple as raising the level. For example, the user wanted 80 Hz tones to appear louder. In an eq, those tones are raised by +3 db. This would make 80 Hz frequencies louder, however, the eq is digitally amplifying the signal. Digital audio has a maximum loudness it can achieve, and if that loudness gets exceeded, the sound will distort. There is a simple solution to this problem. Most equalizers have a feature that sets the maximum gain across all bands to 0db. This is basically shifting the entire equalization down until the top most slider is equal to 0db. In other words, instead of making a sound louder, you're making the rest of the frequency spectrum quieter. In order to make up for this loss in gain, more analog amplification is required to meet the difference.
The second limitation of EQ is that it can't make a bad piece of hardware good. Eq can definitely make any piece of hardware sound better, but it can't turn a $10 gas station headphone into something that would please an audiophile. If a piece of hardware isn't offering a fidelity the user desires, the user should look at better hardware to satisfy their desires.
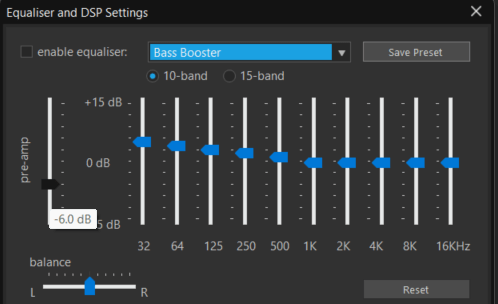
This is an example of the bass boost eq profile in musicbee. The preamp is set to -6dB, which is larger in magnitude than the largest magnitude of the boosted frequencies. This ensures that no peaking occurs on the output. Frequencies below 1kHz are gradually increased, emphasizing these frequencies in playback. Frequencies around 32 Hz receive the greatest effect.
Japanese Music Genres
There are multiple genres that are distinctly Japanese, all with different origins and established in different periods of time. The following are modern genres that still hold relevance within a majority of listeners today:
Vocaloid
Vocaloid & Vocaloid
The genre vocaloid is name after the voice synth Vocaloid (by Yamaha). But as a genre, it counts every song produced by voice synth. For example: Synthesizer V, CeVIO, OpenUtau etc.
Vocaloid remains an icon of the early to mid 2000s. With the help of NicoNico Douga, a japanese video sharing platform, Vocaloid would skyrocket in popularity within the underground doujin scene. Hatsune Miku’s cover of "Ievan Polkka" in particular would garner the genre massive exposure. (A remastered version of the track can be heard here.)
Vocaloid is much broader than just Hatsune Miku. With its extensive array of voice banks, Vocaloid encompasses a huge variety of genres and styles within its own umbrella of synthetically constructed vocals. While not a concrete number, there are easily around 100 officially licensed Vocaloid voice banks as of 2024, not counting rereleases. Factoring in vocal synths, as well as the publicly available utau voice banks, this number becomes astronomically higher. Essentially, the capabilities of Vocaloid software allow for an endless amount of user expression.
Vocaloid would slowly gain traction after the release of Vocaloid 2. The doujin scene in particular would latch onto the easy to use software to make up for the lack of a vocalist. The voicebanks were there to use, and could be warped to whatever sound and aesthetic the producer desired. Hatsune Miku in particular would become a sort of icon for the genre, with her design being plastered all across the internet and Japan alike. Sega would consistently tie Hatsune Miku into spinoff games, such as the Project Diva rhythm game series. The internet would create animations in software such as Adobe Flash, as well as fanart of Hatsune Miku. The art and animations would accompany releases in a sort of Vocaloid mixed media production. All of this tied into mass exposure for the genre, and especially the brand. Even today, these traditions are still being honored in modern Vocaloid releases.
Everything from jpop to metal to hard trance is fair game for Vocaloid. While the term refers to a genre in of itself, it's more akin to how non-specific something like “female vocals” would be. The only qualification for a Vocaloid song is for it to contain vocals from some sort of vocaloid/utau voicebank. Its low barrier to entry has found a niche in pretty much every modern genre.
Some popular vocaloid producers consist of Kikuo, PinocchioP, Wowaka and Mitchie M.
Shibuya-kei
Shibuya-kei was born in the 90s and died in the early 2000s. The Shibuya part of the name points to the origin of sales of the music and kei points to a (supposed) type of person of the Shibuya district. The sound is most concretely pop, but it pulls its inspiration mostly from various different types of jazz.
Bossa nova in particular seems to be a large inspiration. The genre featured a lot of french vocalists, and their musical influences bled into the genre. This can be seen within Shibuya-kei’s most recognizable group, Pizzicato Five, as well as vocalists such as Kahimi Karie. Cornelius more or less spearheaded the genre, with many self compositions as well as compositions released under their own label “Trattoria” dominating the scene. While the genre was quick to start and quick to die, it left an impact. Foreign listeners in particular were fond of the genre and it still remains an influential genre within Japan.
Honorable mention Cibo Matto’s Stero Type A.
Denpa
Denpa music is defined vaguely, but it consists of music the average person would deem “weird”. Not in the avant garde experimental kind of way but usually in the more otaku influenced… synth rainbow vomit kind of way. Denpa music doesn’t really pay its origin to any one subculture in particular, however, it is commonly associated with the otaku. Its otaku association, and eventually catering of the genre to, helped to proliferate and solidify its infamy.
The actual origin of the genre lay in songs that were considered creepy. Repeated nonsensical vocals over cutesy soundfonts made for an uncomfortable listening session. This would further develop with the rise of the term “denpa” as a way to describe delusional and mentally unwell individuals (more can be read about its origins here). The genre of music would evolve into songs that contained menhera themes, otaku themes, or themes most of Japanese society at the time would not be comfortable listening to. A lot of parallels would be drawn to genres such as jpop and jcore, however, most people who make denpa music tend not to associate with other genres in order to keep its underground origins intact.
Popular artists/producers/groups/circles in the scene consist of Nanahira and iOSYS.
Jpop
Jpop, Japanese pop, is pop music with origins in Japan. The sound is distinct from western pop, in that a lot of influences from Shibuya-kei (see above) and modern mexican pop can be observed within the scene. The genre gets marketed internationally much like that of Kpop, but to a less impactful degree. Due to a high otaku presence within the genre, there arise opportunities for more risky, experimental productions to be funded. With the large ethnographic appeal to the Jpop scene, a unique situation arises where vastly different styles of Jpop are allowed to rise to the top. The genre can be perceived as being more diverse than a western counterpart, and it probably is to a degree.
Popular Jpop artists to check out could be REOL, Ado, or Haru Nemuri.
Doujin (music)
Doujin, specifically Doujin music, is the otaku indie scene of music within Japan. While not all of it is explicitly otaku, a large majority of it is associated with the culture. This is music being released on CD-Rs at events such as Comiket, Reitaisai, or M3. The music can also be released digitally should the circle/individual want it. There's no explicit genre, but the releases are usually from small and tightly knit groups called circles (if not individuals).
A couple doujin artist/circles worth checking out consist of Shibayan Records, Release Hallucination, or Akatsuki Records.
Jcore
Jcore specifically refers to the Japanese core style music scene, although the Japanese electronic scene as a whole is incredibly influential. Many international electronic music fans are aware of and actively listening to the Japanese electronic music scene at large. A big reason for this is the exporting of rhythm games from japan. A majority of doujin music exists within the Jcore sphere, and many doujin music circles sell rights to their music to rhythm game companies. As such, the Jcore scene sees mass international exposure to people within the rhythm game subculture.
Producers in the J-Core scene worth checking out consist of DJ Sharpnel and TORIENA.
Idol
Idol music falls under the multi-media umbrella of Japanese idol culture. Idols are teenage girls that are over-marketed into superstars for an otaku audience. Ideas of escapism, maximalism, and aesthetics are core to the subculture. Idols normally don't have prior knowledge from a performance background. Rather, studios will engineer idols into performance artists with strict and unorganized schedules. Many social freedoms are restricted, such as visiting family and drinking/smoking. A distinct image must be upheld, an image that has been core to the subculture since the beginning.
The music itself consists of a variety of genres. Denpa, Jpop, and Jrock are all fair game for idol groups. Experimentation is welcome within the genre, but the music is going to be dictated by the studio that hired the idol. Groups such as Babymetal are iconic for combining metal with more popish, traditional idol vocals.
You can check out AKB48, BABYMETAL and Hoshimachi Suisei.
Where to purchase Japanese Music?
Give the Wotaku music page a look. Both Ototoy and Bandcamp house a lot of high quality japanese music, both from the mainstream as well as the underground. Each storefront allows the user to save music purchases to an account. As long as the service is live, music can be redownloaded indefinitely. Both services also offer lossless, as well as 24 bit lossless.
For physicals, Suruga-ya is a Japanese second hand market with a good english translation and international shipping feature. Otherwise, a website such as booth-pm or melonbooks can be navigated with minimal trouble, however, a proxy shipping service must be utilized.